|
 |
Understanding Object Dynamics for Interactive Image-to-Video Synthesis (2021)
Blattmann, A., Milbich, T., Dorkenwald, M. and Ommer, B.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2021
What would be the effect of locally poking a static scene? We present an approach that learns naturally-looking global articulations caused by a local manipulation at a pixel level. Training requires only videos of moving objects but no information of the underlying manipulation of the physical scene. Our generative model learns to infer natural object dynamics as a response to user interaction and learns about the interrelations between different object body regions. Given a static image of an object and a local poking of a pixel, the approach then predicts how the object would deform over time. In contrast to existing work on video prediction, we do not synthesize arbitrary realistic videos but enable local interactive control of the deformation. Our model is not restricted to particular object categories and can transfer dynamics onto novel unseen object instances. Extensive experiments on diverse objects demonstrate the effectiveness of our approach compared to common video prediction frameworks.
|
 |
Stochastic Image-to-Video Synthesis using cINNs (2021)
Dorkenwald, M., Milbich, T., Blattmann, A., Rombach, R., Derpanis, K. and Ommer, B.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2021
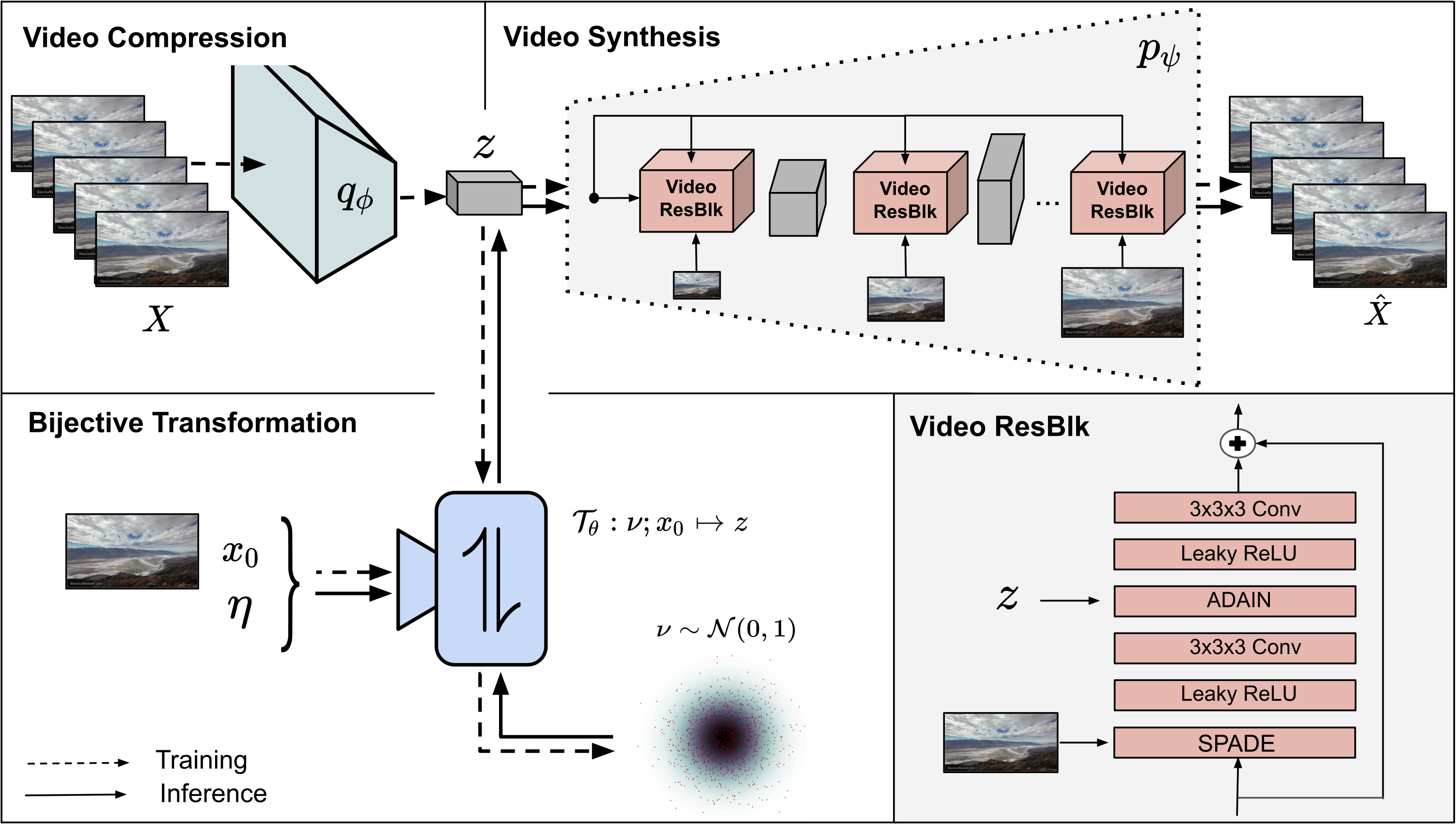
Video understanding calls for a model to learn the characteristic interplay between static scene content and its dynamics: Given an image, the model must be able to predict a future progression of the portrayed scene and, conversely, a video should be explained in terms of its static image content and all the remaining characteristics not present in the initial frame. This naturally suggests a bijective mapping between the video domain and the static content as well as residual information. In contrast to common stochastic image-to-video synthesis, such a model does not merely generate arbitrary videos progressing the initial image. Given this image, it rather provides a one-to-one mapping between the residual vectors and the video with stochastic outcomes when sampling. The approach is naturally implemented using a conditional invertible neural network (cINN) that can explain videos by independently modelling static and other video characteristics, thus laying the basis for controlled video synthesis. Experiments on four diverse video datasets demonstrate the effectiveness of our approach in terms of both the quality and diversity of the synthesized results.
|
 |
Behavior-Driven Synthesis of Human Dynamics (2021)
Blattmann, A., Milbich, T., Dorkenwald, M. and Ommer, B.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2021
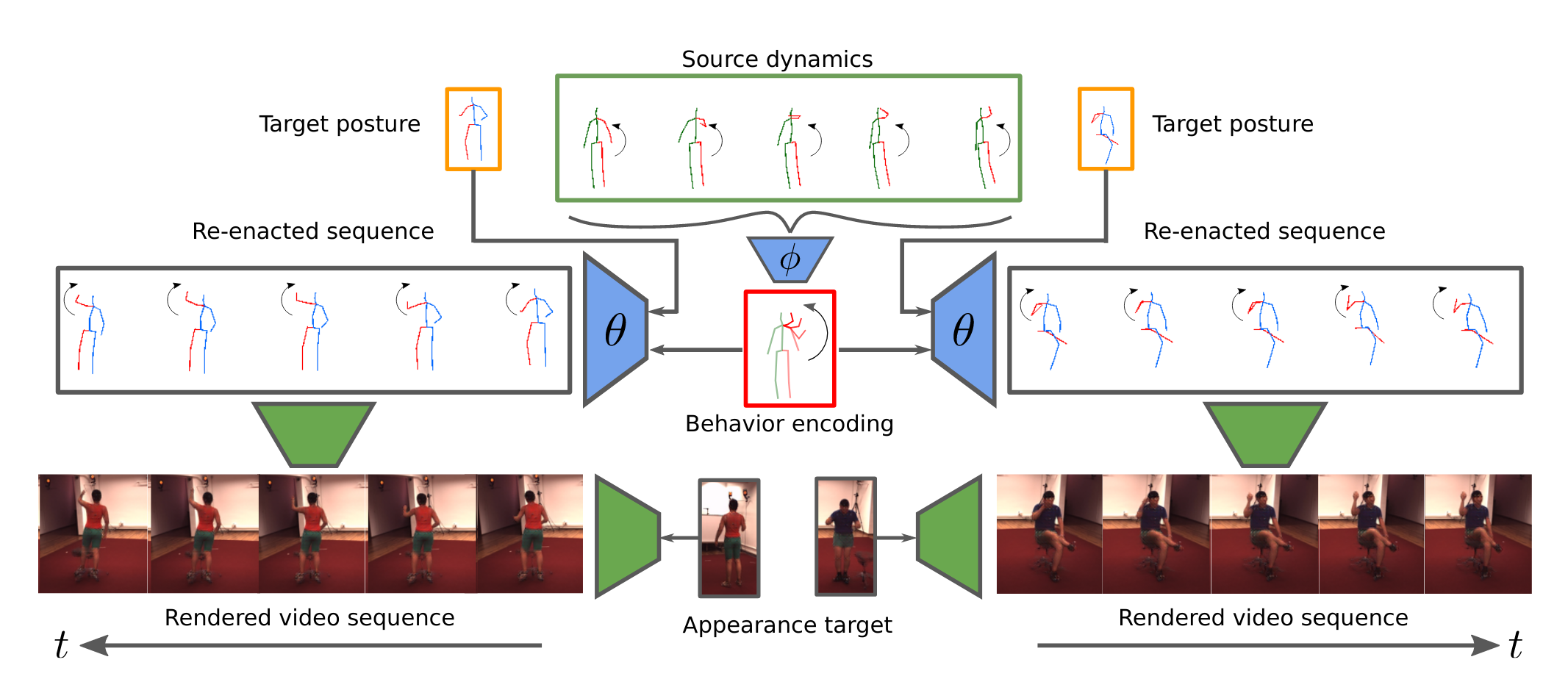
Generating and representing human behavior are of major importance for various computer vision applications. Commonly, human video synthesis represents behavior as sequences of postures while directly predicting their likely progressions or merely changing the appearance of the depicted persons, thus not being able to exercise control over their actual behavior during the synthesis process. In contrast, controlled behavior synthesis and transfer across individuals requires a deep understanding of body dynamics and calls for a representation of behavior that is independent of appearance and also of specific postures. In this work, we present a model for human behavior synthesis which learns a dedicated representation of human dynamics independent of postures. Using this representation, we are able to change the behavior of a person depicted in an arbitrary posture, or to even directly transfer behavior observed in a given video sequence. To this end, we propose a conditional variational framework which explicitly disentangles posture from behavior. We demonstrate the effectiveness of our approach on this novel task, evaluating capturing, transferring, and sampling fine-grained, diverse behavior, both quantitatively and qualitatively.
|
 |
Unsupervised behaviour analysis and magnification (uBAM) using deep learning (2021)
Brattoli, B., Buechler, U., Dorkenwald, M., Reiser, P., Filli, L., Helmchen, F., Wahl, A.-S. and Ommer, B.
Nature Machine Intelligence 2021
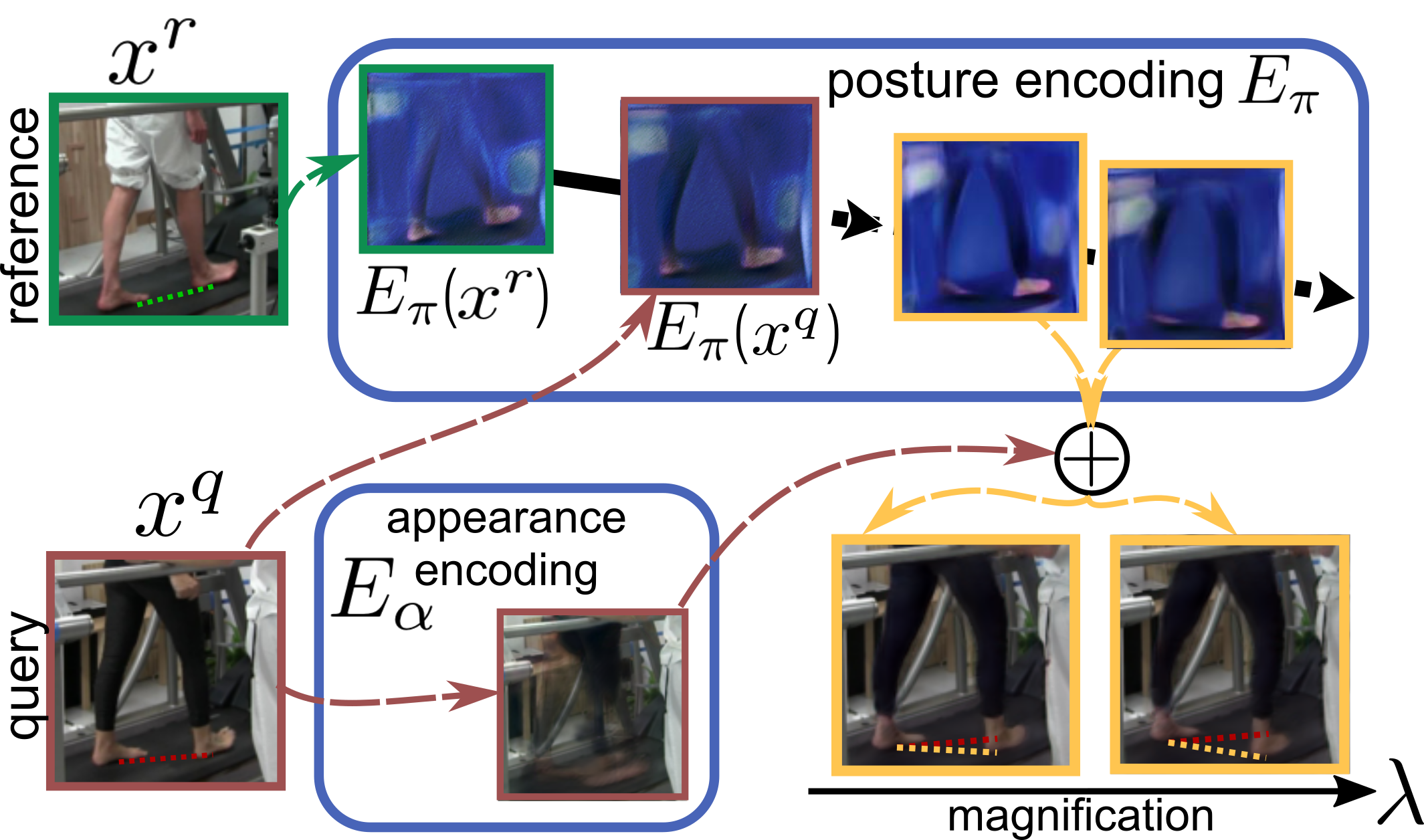
Motor behaviour analysis is essential to biomedical research and clinical diagnostics as it provides a non-invasive strategy for identifying motor impairment and its change caused by interventions. State-of-the-art instrumented movement analysis is time- and cost-intensive, because it requires the placement of physical or virtual markers. As well as the effort required for marking the keypoints or annotations necessary for training or fine-tuning a detector, users need to know the interesting behaviour beforehand to provide meaningful keypoints. Here, we introduce unsupervised behaviour analysis and magnification (uBAM), an automatic deep learning algorithm for analysing behaviour by discovering and magnifying deviations. A central aspect is unsupervised learning of posture and behaviour representations to enable an objective comparison of movement. Besides discovering and quantifying deviations in behaviour, we also propose a generative model for visually magnifying subtle behaviour differences directly in a video without requiring a detour via keypoints or annotations. Essential for this magnification of deviations, even across different individuals, is a disentangling of appearance and behaviour. Evaluations on rodents and human patients with neurological diseases demonstrate the wide applicability of our approach. Moreover, combining optogenetic stimulation with our unsupervised behaviour analysis shows its suitability as a non-invasive diagnostic tool correlating function to brain plasticity.
|
 |
Unsupervised Magnification of Posture Deviations Across Subjects (2020)
Dorkenwald, M., Büchler, U. and Ommer, B.
IEEE Conference on Computer VIsion and Pattern Recognition (CVPR) 2020
Analyzing human posture and precisely comparing it across different subjects is essential for accurate understanding of behavior and numerous vision applications such as medical diagnostics or sports. Motion magnification techniques help to see even small deviations in posture that are invisible to the naked eye. However, they fail when comparing subtle posture differences across individuals with diverse appearance. Keypoint-based posture estimation and classification techniques can handle large variations in appearance, but are invariant to subtle deviations in posture. We present an approach to unsupervised magnification of posture differences across individuals despite large deviations in appearance. We do not require keypoint annotation and visualize deviations on a sub-bodypart level. To transfer appearance across subjects onto a magnified posture, we propose a novel loss for disentangling appearance and posture in an autoencoder. Posture magnification yields exaggerated images that are different from the training set. Therefore, we incorporate magnification already into the training of the disentangled autoencoder and learn on real data and synthesized magnifications without supervision. Experiments confirm that our approach improves upon the state-of-the-art in magnification and on the application of discovering posture deviations due to impairment.
|
 |
Unsupervised Video Understanding by Reconciliation of Posture Similarities (2017)
Milbich, T., Bautista, M., Sutter, E., Ommer, B.
IEEE International Conference on Computer Vision (ICCV) 2017
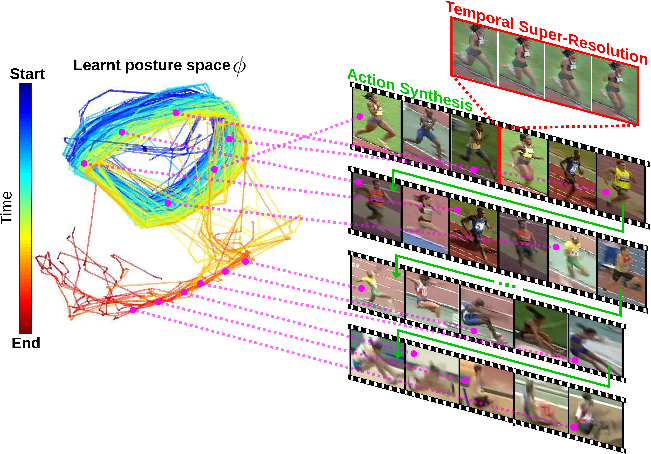
Understanding human activity and being able to explain it in detail surpasses mere action classification by far in both complexity and value. The challenge is thus to describe an activity on the basis of its most fundamental constituents, the individual postures and their distinctive transitions. Supervised learning of such a fine-grained representation based on elementary poses is very tedious and does not scale. Therefore, we propose a completely unsupervised deep learning procedure based solely on video sequences, which starts from scratch without requiring pre-trained networks, predefined body models, or keypoints. A combinatorial sequence matching algorithm proposes relations between frames from subsets of the training data, while a CNN is reconciling the transitivity conflicts of the different subsets to learn a single concerted pose embedding despite changes in appearance across sequences. Without any manual annotation, the model learns a structured representation of postures and their temporal development. The model not only enables retrieval of similar postures but also temporal super-resolution. Additionally, based on a recurrent formulation, next frames can be synthesized.
Behavior Analysis
Self-Supervised Learning
Arxiv
|
 |
LSTM Self-Supervision for Detailed Behavior Analysis (2017)
Brattoli, B., Büchler, U., Wahl, A.-S., Schwab, M. E. and Ommer, B.
IEEE Conference on Computer VIsion and Pattern Recognition (CVPR) 2017
Neural networks have greatly boosted performance in computer vision by learning powerful representations of input data. The drawback of end-to-end training for maximal overall performance are black-box models whose hidden representations are lacking interpretability: Since distributed coding is optimal for latent layers to improve their robustness, attributing meaning to parts of a hidden feature vector or to individual neurons is hindered. We formulate interpretation as a translation of hidden representations onto semantic concepts that are comprehensible to the user. The mapping between both domains has to be bijective so that semantic modifications in the target domain correctly alter the original representation. The proposed invertible interpretation network can be transparently applied on top of existing architectures with no need to modify or retrain them. Consequently, we translate an original representation to an equivalent yet interpretable one and backwards without affecting the expressiveness and performance of the original. The invertible interpretation network disentangles the hidden representation into separate, semantically meaningful concepts. Moreover, we present an efficient approach to define semantic concepts by only sketching two images and also an unsupervised strategy. Experimental evaluation demonstrates the wide applicability to interpretation of existing classification and image generation networks as well as to semantically guided image manipulation.
Behavior Analysis
Self-Supervised Learning
Paper
|
 |
Optogenetically stimulating the intact corticospinal tract post-stroke restores motor control through regionalized functional circuit formation (2017)
Wahl, A.-S., Büchler, U., Brändli, A., Brattoli, B., Musall, S., Kasper, H., Ineichen, BV., Helmchen, F., Ommer, B., Schwab, M. E.
Nature Communications 2017
Current neuromodulatory strategies to enhance motor recovery after stroke often target large brain areas non-specifically and without sufficient understanding of their interaction with internal repair mechanisms. Here we developed a novel therapeutic approach by specifically activating corticospinal circuitry using optogenetics after large strokes in rats. Similar to a neuronal growth-promoting immunotherapy, optogenetic stimulation together with intense, scheduled rehabilitation leads to the restoration of lost movement patterns rather than induced compensatory actions, as revealed by a computer vision-based automatic behavior analysis. Optogenetically activated corticospinal neurons promote axonal sprouting from the intact to the denervated cervical hemi-cord. Conversely, optogenetically silencing subsets of corticospinal neurons in recovered animals, results in mistargeting of the restored grasping function, thus identifying the reestablishment of specific and anatomically localized cortical microcircuits. These results provide a conceptual framework to improve established clinical techniques such as transcranial magnetic or transcranial direct current stimulation in stroke patients.
|
 |
Spatiotemporal Parsing of Motor Kinematics for Assessing Stroke Recovery (2015)
Antic, B., Büchler, U., Wahl, A.-S., Schwab, M. E., Ommer, B.
Medical Image Computing and Computer-Assisted Intervention (MICCAI) 2015
Stroke is a major cause of adult disability and rehabilitative training is the prevailing approach to enhance motor recovery. However, the way rehabilitation helps to restore lost motor functions by continuous reshaping of kinematics is still an open research question. We follow the established setup of a rat model before/after stroke in the motor cortex to analyze the subtle changes in hand motor function solely based on video. Since nuances of paw articulation are crucial, mere tracking and trajectory analysis is insufficient. Thus, we propose an automatic spatiotemporal parsing of grasping kinematics based on a max-projection of randomized exemplar classifiers. A large ensemble of these discriminative predictors of hand posture is automatically learned and yields a measure of grasping similarity. This non-parametric distributed representation effectively captures the nuances of hand posture and its deformation over time. A max-margin projection then not only quantifies functional deficiencies, but also back-projects them accurately to specific defects in the grasping sequence to provide neuroscience with a better understanding of the precise effects of rehabilitation. Moreover, evaluation shows that our fully automatic approach is reliable and more efficient than the prevalent manual analysis of the day.
Behavior Analysis
Multiple Instance Learning
Paper
|


